

webスクレイピングしたり、SNS情報をスクレイピングしてワードクラウドを作ろうとした場合、やっぱり日本語で作りたいですよね。
前回のPythonでワードクラウドを作ろうで作ったプログラムでは日本語の文章をそのまま入れてもワードクラウドができません。
それは、wordcloudモジュールが日本語の単語を区別できないから。
英文は単語、接続詞などでそれぞれスペースで区切られていて、単語が明確になっています。
対して日本語はどこからどこまでが1つの単語かプログラムでは判断しづらいですね。
と、言うことは日本語の文章も、単語ごとに分解してスペース区切りにできればワードクラウド化ができるということです!
日本語文のテキストデータを読み込んでワードクラウドを作るプログラムを書いていきます。
形態素解析モジュールMeCabをインストール

MeCab(和布蕪・めかぶ)
日本語の自然言語テキストデータを、名詞、品詞、動詞など最小単位に分解して判別するモジュール。
MeCabの他にもモジュールはありますが、一番情報が多そうなMeCabを使っていきます。
解析モジュールと併せて、辞書データも必要らしいですがWindows版は辞書もプリセットされているのでそこらも楽々。
公式?のダウンロードよりWindows用のexeをダウンロードして、exe実行でインストールをしていきます。
途中で辞書データの文字コード指定があるので、UTF-8でインストールしました。
mecab-python-windowsをインストール
MeCabのインストールだけでは、Windowsで使えるようになっただけで、Pythonのプログラムからはまだ使えない。ので橋渡しの役割のモジュールを使います。
ちょっと前はmecab-pythonのソースを入手してゴニョゴニョする必要があったようですが・・・
今はmecab-python-windowsを用意してくれた先人がいるので、ありがたく使っていきます。@Yukinoiさんありがと。
インストールはpip使ってコマンド一行でOK。
|
1 |
pip install mecab-python-windows |
形態素解析とスペース区切りへ成形
|
1 2 3 4 |
import MeCab m = MeCab.Tagger('') parsed = m.parse('私はブログを書いている') |
この時点でparsedが最小単位の単語と評価が行われたデータになります。私 名詞,代名詞,一般,*,*,*,私,ワタシ,ワタシ
は 助詞,係助詞,*,*,*,*,は,ハ,ワ
ブログ 名詞,一般,*,*,*,*,*
を 助詞,格助詞,一般,*,*,*,を,ヲ,ヲ
書い 動詞,自立,*,*,五段・カ行イ音便,連用タ接続,書く,カイ,カイ
て 助詞,接続助詞,*,*,*,*,て,テ,テ
いる 動詞,非自立,*,*,一段,基本形,いる,イル,イル
|
1 |
splitted = ' '.join([x.split('\t')[0] for x in hoge.splitlines()[:-1]]) |
で単語だけを半角スペースで結合させた文に変えていきます。私 は ブログ を 書い て いる
単語がスペースで区切られているので、wordcloudモジュールに入れればなんとかなりそうですね。
元となるテキストはテキストファイルから読み込んで、進めていきます。
wordcloudへ投入したら・・・でき・・・ない
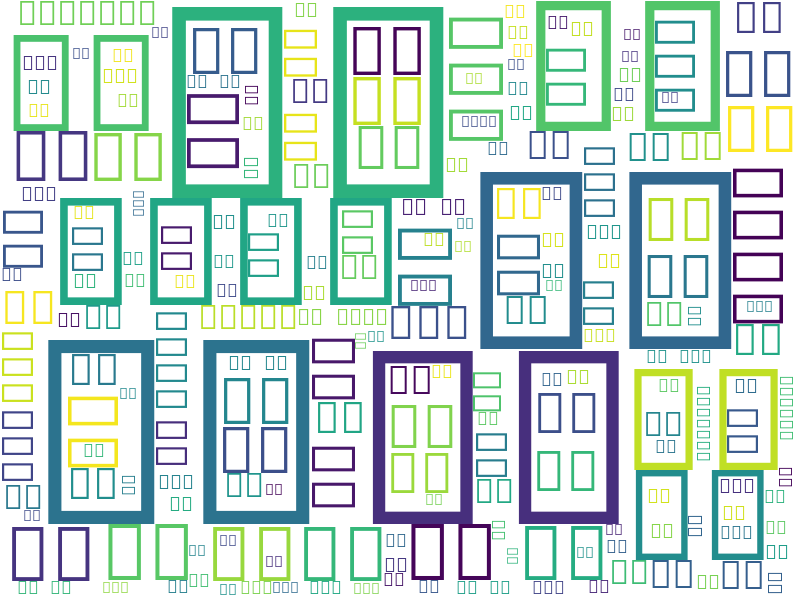
|
1 2 3 4 5 6 |
#分割テキストからwordcloudを生成 wordc = wordcloud.WordCloud(background_color='white', width=800, height=600).generate(splitted) #画像ファイルとして保存 wordc.to_file('wordcloud.png') |
画像ファイルができたけど・・・文字が全部化けて□になっとる。
使用するフォントを日本語対応するものに指定していきます。
【2019/3/31:編集 フォントパスをフルパスからファイル名へ変更】
|
1 2 3 4 |
#分割テキストからwordcloudを生成・フォント指定 wordc = wordcloud.WordCloud(font='HGRGM.TTC', background_color='white', width=800, height=600).generate(splitted) |
これで、完成です。

助詞と助動詞を含めないでワードクラウド化
ワードクラウドに含めたいのは名詞とか動詞ですよね。
助詞、助動詞が含まれるのはあんまり望ましくない。
かと言って、wordcloudの除外キーワード作るの大変そう。と思っていたら。
「助詞、助動詞」を除いて、スペース区切りの文章を成形させる。
|
1 |
splitted = ' '.join([x.split('\t')[0] for x in hoge.splitlines()[:-1] if x.split('\t')[1].split(',')[0] not in ['助詞', '助動詞']]) |
単語をスペース区切りで結合させる際に、
解析結果が「助詞」または「助動詞」の場合は除く。という条件を付け加えました。
これで作ったワードクラウドがこちら

マスク画像使って

コード全文
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 |
from PIL import Image import numpy as np import wordcloud, codecs import MeCab file = codecs.open('ibuka-speech.txt','r', 'utf-8', 'ignore') text = file.read() msk = np.array(Image.open('app-visual-0.png')) m = MeCab.Tagger('') text = text.replace('\r','') parsed = m.parse(text) #助詞、助動詞を除いて単語結合 splitted = ' '.join([x.split('\t')[0] for x in parsed.splitlines()[:-1] if x.split('\t')[1].split(',')[0] not in ['助詞', '助動詞']]) wordc = wordcloud.WordCloud(font_path='HGRGM.TTC', background_color='white', mask=msk, contour_color='steelblue', contour_width=2).generate(splitted) wordc.to_file('sample-wordCloud-jpn.png') |
これだけのコード量でできちゃうのですね~
ちなみに元文章はソニー創立者の1人、井深大さんが起草した
「東京通信工業株式会社設立趣意書」を使いました。
コメント